Operating System Concepts: Memory Management
In the foregoing chapters we actually discussed about CPU sharing among processes. If we want to execute a process, it should be first loading into memory, so the memory will be shared by other processes simultaneously to allow multiprogramming. In chapter 8 and chapter 9, we will focus on memory sharing.
Memory-management Algorithms
Contiguous Memory Allocation
In contiguous memory allocation, each process (OS process or user process) is contained in a single section of memory that is contiguous to the section containing the next process.
Problem 1 : Protection
How to protect the memory address space from accessing by others?
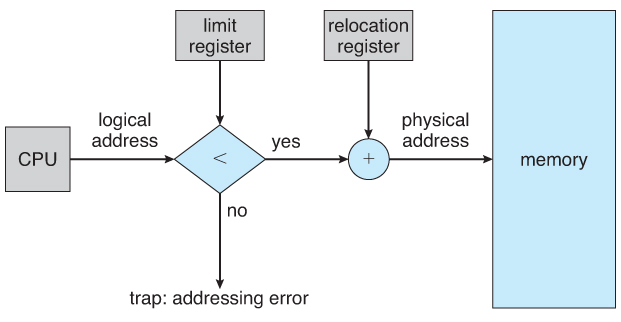
Since the process is contiguous in memory, which means we can use two registers for each process to limit their address accessing: limit register and relocation register. When CPU shceduler selects a process for execution, the dispatcher loads the relocation and limit registers as part of context switch, then MMU will maps the logical address dynamically by adding the two values to specific physical address.
Problem 2 : Allocation
How to share memory among processes?
One simple methods, mutiple-partition: dividing memory into several fixed-sized partitions, and each partition may cotain exactly one process. This method will cause a bunch of memory waste, typically in internal fragmentation.
In the variable-partition shceme, the operating system may keep a table indicating which parts of memory are available and which are occupied. In general, the memory blocks available comprise a set of holes of various size scattered throughout memory. When a process is to swapped into memory, OS will find an free block that is large enough. If the hole is too large, it is split into two parts, one is allocated to the arriving process; the other is returned to the set of holes, these adjacent holes are merged to form one larger hole.
As processes are loaded and removed from memory, the free memory space is broken into little, which are called external fragmentation. It exists then there is enough total memory space to satisfy a request but the available spaces are not contiguous!
One solution to the external-fragmentation problem is to permit the logical address space of the processes to be noncontiguous. Two complementary techniques achieve this solution: segmentation and paging.
Segmentation
Hardware can provide a memory mechanism that mapped the programmer’s view to the actual physical memory, which system would have more freedom to manage memory, while the programmer would have a more natural programming environment (uncoupling).
In sementation shceme, a logical address space is a collection of segments, each has a name and a length. The programmer specifies each address by two quantities: a segment name and an offset, as .
In order to map the two-dimentional logical address to one-dimentional physical address, we use a datastructure called segment table. Each entry of segment table has a segment base and a segment limit (similar to conitiguous allocation). The use of a segment table is illustrated below, where s stands for a segment number and d referred to a s the offset from base address of the segment.

Paging
Paging is another memory-management scheme that permits the physical adress space of a process to be noncontiguous.
The basic method for implementing paging involves breaking physical memory into fixed-sized blocks caclled frames and breaking logical memory into blocks of the same size called pages. In this way, paging avoids external fragmentation and the need for compaction.
1 | command for querying page size in Linux |
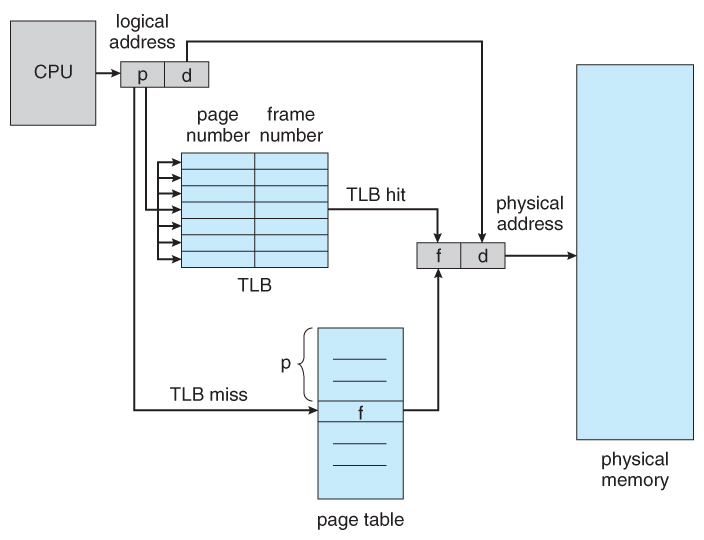
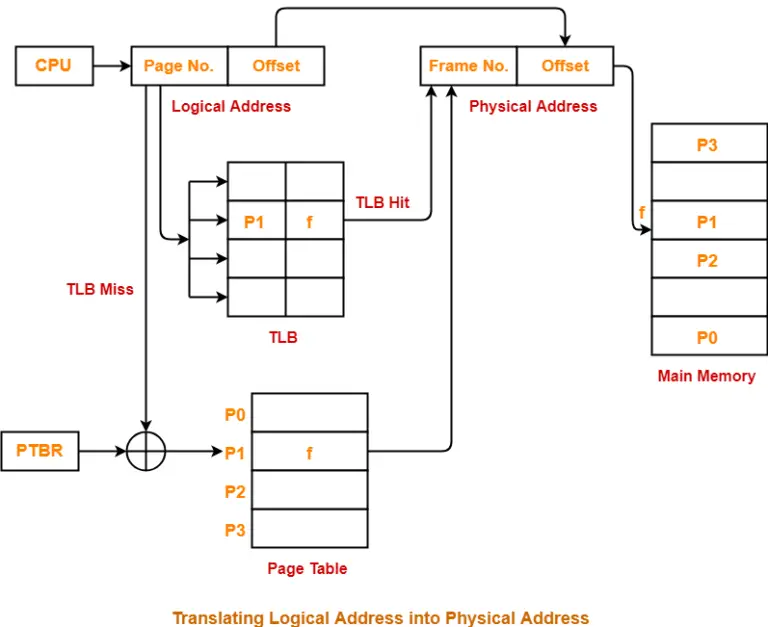
Every address generated by CPU is divided into two parts: a page number § and a page offset (d). The page number is used as an index into a page table. The page table contains the base address of each frame in physical memory, which maps logical page to phsical frame. Below is the paging model:
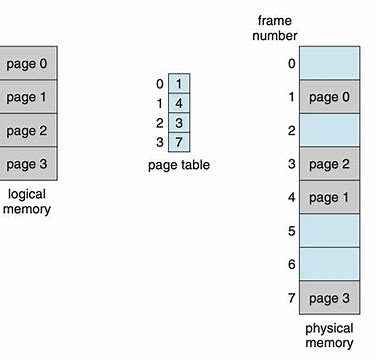
Notice that frames are allocated as uints, so we would always allocated more memory to process than it needs, which results in internal fragmentation.
Hardware Support - TLB
Some operating system allocate a page table for each process, so a pointer to the page table is stored with the other register values in PCB (e.g., xv6 kernel/proc.h). Other operating systems provide one or at most a few page tables, which decreases the overhead involbed when process are context-switched.
Page table can be implemented as a set of dedicated registers. If we want to access location i, we must first index into the page table, then using the frame number in table entry to access the desired place. With this shceme, two memory accesses are needed.
In pratice, we use a special, small, fast-lookup hardware cache called a translation look-aside buffer (TLB). The TLB is associative, high-speed memory. It stores recently used page table entries, which are used for address translation. When the CPU needs to access a memory location, it first checks the TLB. If the required address translation is found in the TLB (a TLB hit), the access can be completed very quickly, usually in a few clock cycles. If the page number is not in the TLB (a TLB miss), a memory reference to the page table must be made, then we obtain the fram number from memory , and in addition, add the page number and frame numer to the TLB.
Virtual Memory
Segmentation and paging are fundamental memory-management strategies that bridge the gap between the programmer’s view of a continuous memory space and the reality of physical memory. From a programmer’s perspective, memory appears as a seamless, contiguous expanse. However, in the physical realm, memory is divided into blocks scattered across various locations.
Segmentation divides the program into logical segments such as the code segment, data segment, and stack segment. Each segment is a continuous block of virtual memory, which is then mapped to different parts of the physical memory. Paging, on the other hand, partitions both virtual and physical memory into fixed-size pages. These pages are used to establish a mapping relationship between the virtual and physical memory spaces.
Virtual memory builds upon these segmentation and paging mechanisms. It extends the concept by enabling a mapping between physical memory pages and blocks in the back storage, typically a hard disk. When a process needs more memory than is currently available in physical memory, the operating system can swap out less-used pages from the physical memory to the back storage and bring in the required pages. This process creates an illusion for each process, allowing it to operate as if it has access to a larger memory space than the actual physical memory.
Mechanism
1. Demand Paging
When a executable program is to be loaded to RAM, we can load the entire one in physical memory at execution time, but the fact is that we may not initially need the entire program in memory. We can just load pages only as they are needed. This technique is known as demand paging.
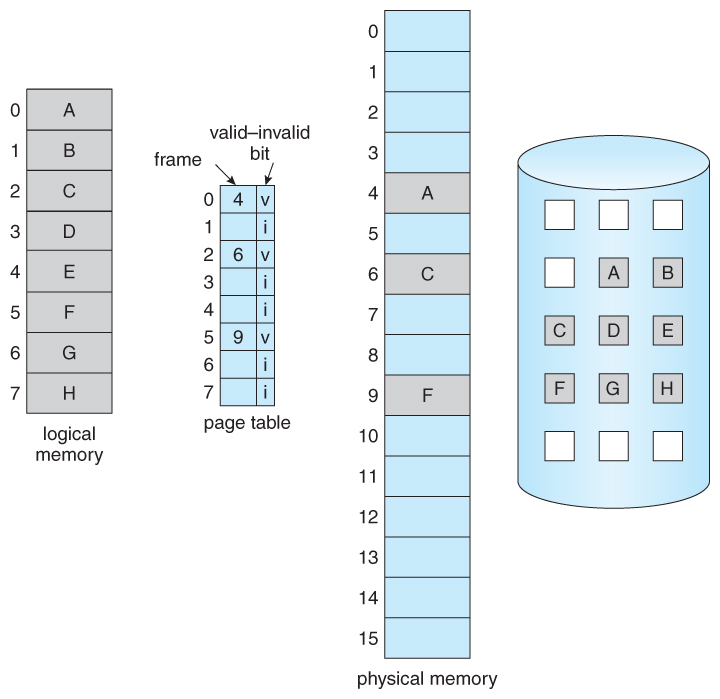
First we need some form of hardware support to tell whether the pages are in memory or on the disk. That is valid-invalid bit:
- valid bit: The associated page is both legal (belongs to that process) and in memory.
- invalid bit: The page is either not valid or is currently on the disk.
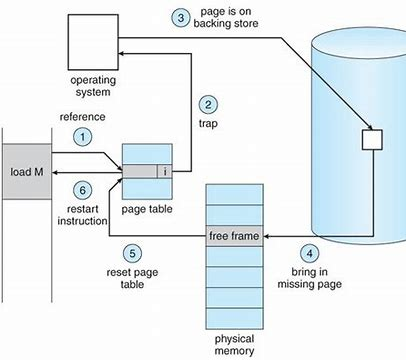
If access to a page marked invalid, it will cause a page fault, then making a trap (syscall) to the operating system. The procedudre for handling the page fault is straightforward:
- Check an internal table to determine whether the access is valid.
- Invalid, terminate the process; Valid but page not in memory, now page it in.
- Find a free frame (frame allocation).
- Schedule a disk operation to read that page into frame.
- Disk read completes, modify internal table and update page table (set valid bit).
- Restart the instruction that was interrupted by the trap.
2. Copy-on-Write
With demand paging, we can easily start a process with fork() by just loading the page that contains the first instruction. In fact, fork() works by creating a copy of parent’s address space for child. Child process and parent process are in their own virtual (logical) address space, but actually they share the same pages, which is called copy-on-write pages. When child edit the variable in its address space or invoke the exec() syscall, the operating system will then copy the edited page for child, left others pages shared. This technique is known as copy-on-write.
Copy-on-Write (COW) is an optimization technique in virtual memory management where multiple processes share the same physical memory pages until one process tries to modify the shared page. At that point, a private copy of the page is made for the writing process, allowing safe modification without affecting others.
- When either process tries to write to a shared page:
- A page fault occurs.
- The operating system:
- Allocates a new physical page.
- Copies the contents of the original page to the new page.
- Updates the page table of the writing process to point to the new (private) page with write access.
- Now each process has its own copy of that page.
Page Replacement
When there is enough free frames in memory, we will not get trouble in physical frame allocation in page swapping. But what about there is no free frame on free-frame list? Then we may swap out a process and free all its frames, it works well in some circumstances (in thrashing below). Here we introduce a common solution - page replacement.
Page replacement together with frame allocation are the two fundamental techniques to implement demand paging:
- Frame-allocation alogorithm: Decide how many frames to allocate to each process.
- Page-repalcement alogorithm: Decide which page will be swapped out into disk.
In page replacement, we generally aim to swap out the page that is least likely to be used soon to minimize page faults.
1. FIFO Page Replacement
The FIFO (First-In, First-Out) page replacement algorithm replaces the oldest page in memory — the one that was loaded first.
It uses a simple queue:
- When a new page needs to be loaded and memory is full, the page at the front of the queue is removed.
- The new page is added to the back.
Drawback: It may remove frequently used pages just because they’ve been in memory the longest — leading to more page faults (this is known as Belady’s anomaly).
2. LRU Page Replacement
LRU (Least Recently Used) replaces the page that has not been used for the longest time. The idea is based on the assumption that pages used recently will likely be used again soon.
Implement Methods:
- Using a counter or timestamp (software simulation), every time a page is accessed, record a timestamp. When a replacement is needed, select the page with the oldest timestamp.
- Pros: Easy to implement logically.
- Cons: Costly in time and space to maintain timestamps.
- Using a stack (linked list or array) to store the page. On every access:
- Remove the page from its current position.
- Move it to the top/front (most recently used).
- Using hash map + doubly linked list (efficient LRU cache).
- Hash Map: Maps page numbers to nodes in the list.
- Doubly Linked List: Keeps pages in order of usage — head is most recently used, tail is least.
3. Second-chance Page Replacement
The Second-Chance algorithm is a page replacement strategy that improves on FIFO by giving pages a “second chance” before being replaced. One way to implement this strategy is using circular queue.
Each page has a reference bit:
- When a page is accessed, its bit is set to 1.
- When a page is selected for replacement:
- If its reference bit is 0, it’s replaced.
- If the bit is 1, it’s cleared and the page and find the next page with rerference bit 0 (giving it a second chance).
This way, frequently used pages are less likely to be swapped out.
Reference:
- Operating System Concepts, 9th edition
- ChatGPT 4o