Operating System Concepts: Multithreaded Programming
Key objectives
- Introduce the notion of a thread
- Explicit threading - APIs for thread libraries
- Implicit threading - kernel level thread management
- Examine issues related to mutithreaded programming
Thread Concept
A thread is a basic unit of CPU utilization, in other word, a fundamental unit of CPU execution. It comprises of:
- a thread ID, TID
- a program counter
- a register set
- a stack
And it shares with other threads belonging to the same process: - code section
- data section
- operating-system resources + open files (and other memory management information) + signals (ps: signal handlers are in shared code section)
A thread can also be viewed as a flow of control. A traditional process has a single thread of control.
Since each thread executes independently, each thread has its own understanding of the stack and of the registers.
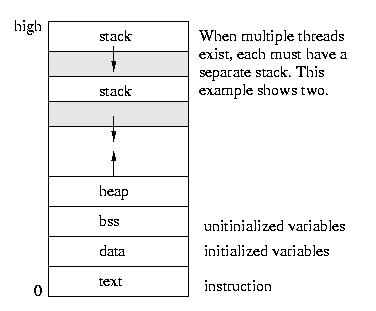
The bad part is that unlike the protection that exists among processes, the operating system can not prevent threads from interfering with each other – they share the same process space.
Motivation
The first question merges in mind is that - why we need to introduce the concept of thread?
A process may have some independent parts of execution which can be executed asynchronically. Take Web browser as an example, it might have one thread displaying images or text (renderer) while another thread retrieves data from network (across NIC), these are relatively different work and need few communication, which can be seen as independent.
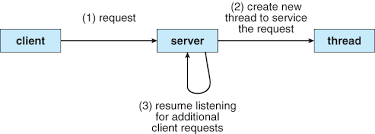
A process might have to handle some duplicate requests. Think about a Web server, it may perform several similar tasks, such as accepting client request for web pages, images or videos. If the web server program runs as a traditional single-threaded process, it can serve only one client at any point since concurrency is not true parellelism! One solution to the problem is to create a separate new process to serve every client. But that’s huge resource consumption because creating a new process is time-consuming and resource-intensive (and we terminate it when task finishes), and it’s in low resource utilization because the process just performs the same tasks as the original process (say, search data in DB and return it to client).
So in this cirsumstance, why not just create a more lightweight process - thread?
Benefits
- Responsiveness: allowing program to continue running even if part of it is blocked or is performing a lengthy operation, thereby increasing reponsiveness to the user
- Resource sharing: sharing the memory and resources of the process to which they belong to, which allows an aplication to have several threads of activity within the same address space
- Economy: more economical to create and context-switch threads
- Scalability: threads can run in parellel on different processing cores, which takes advantage of muticores system
Mechanism of Thread Switching
Switching the CPU from one thread to another belonging to the same process involves suspending the current thread, saving its state (e.g., registers, accumulator), and then restoring the state of the thread being switched to.
The thread switch actually completes at the moment a new program counter is loaded into PC; at that point, the CPU is no longer executing the thread switching code, it is executing code associated with the new thread.
A context switch between threads does the following:
- Save all registers (general-perpose, special and CCs) in TCB (Thread Control Block).
- Then we will save PC. Instead of saving the current PC, we place the return address (found on the stack in the thread’s activation record) in the thread’s context block. When the thread is resumed later, the resuming address loaded into the PC will be the instruction immediately following the
callinstruction that invokedSwitch()earlier. - Once the current thread’s state has been saved, load new values into the registers from the TCB of the next thread. We know that in the perspective of CPU, a context of a process or thread is all about the registers and condition codes (and maybe cache, but not consider here). So when a new stack pointer loaded onto SP, it actually performs “stack switching”.
- So what is the exact point a context switch has taken place? That is, when the current PC is replaced by the saved PC found in the process table. Once the saved PC is loaded,
Switch()is no longer executing; we are now executing instructions associated with the new thread, which should be the instruction immediately following the call toSwitch(). As soon as the new PC is loaded, a context switch has taken place.
Multithreading Model
User Level thread and Kernel Level thread
Support for threads may be provided eitherat the user level, for user threads, or by the kernel, for kernel threads. User threads are supported above the kernel and are managed without kernel support, whereas kernel threads are suported an managed directly by the operating system.
There are two confusing terms, one is “support” and the other is “user/kernel thread”.
To my understading, user level thread and kernel level thread are two abstract concepts. User threads are visible to user/programmer which means they can be manipulated by users. While kernel threads are visible to operating system, they are managed by kernel, and most importantly, they are the actual unit to be scheduled by kernel or to be executed by CPU.
So in order to make a user thread to be executed, a relationship must exist between user threads and kernel threads, that is mapping. The following are the three common ways to establish such a relationship.
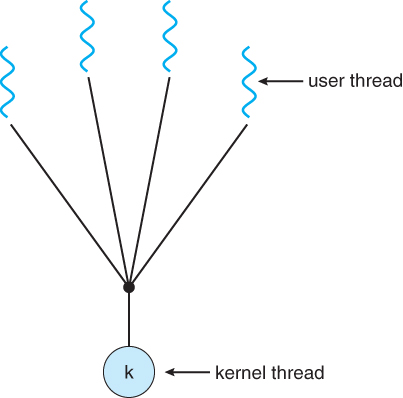
Many-to-One Model
The many-to-one model maps many user threads to a single kernel thread. Thread management (creation, termination, scheduling, etc) is implemented by thread library, so kernel is unaware of these threads and it can only “see” one user thread at any time.
This model is efficient since the management is all done in user level, without diving into kernel mode. However, if a thread calls a blocking system call (e.g. sleep(), wait() or I/O request), the entire process will block. Also, because only one thread can access the kernel at a time, it can’t make use of mutiple processors in muticores environment.
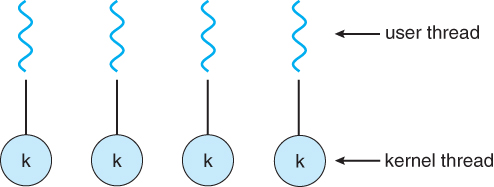
One-to-One Model
The one-to-one model maps each user thread to a kernel thread. It not only provides more concurrency by allowing another thread to run when a thread makes a blocking system call, but also allows mutiple threads to run in parallel in muticores environment.
The only drawback is that creating and manipulating a bunch of kernel threads bring a great overhead and can burden the performance of an application.
Lightweight Process (LWP)
Copy from https://cseweb.ucsd.edu
Kernel threads are great for kernel writers and user threads answer many of the needs of users, but they are not perfect. Consider these examples:
- On a multiprocessor system, only one thread within a process can execute at a time
- A process that consists of many threads, each of which may be able to execute at any time, will not get any more CPU time than a process containing only one thread
- If any thread within a process makes a system call, all threads within that process will be blocked because of the context switch.
- If any user thread blocks waiting for I/O or a resource, the entire process blocks. (Thread libraries usually replace blocking calls with non-blocking calls whenever possible to mitigate this.)
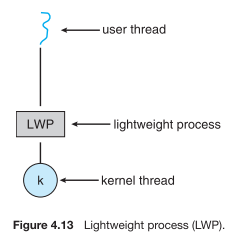
To address these needs, we need to have a kernel supported user thread. That is to say, we need a facility for threads to share resources within a process, but we also need the ability of the kernel to preempt, schedule, and dispatch threads. This type of thread is called a kernel supported user thread or a light-weight process (LWP). A light-weight process is in contrast with a heavy-weight process otherwise known as a process or task.
Our model of the universe has gone from looking like this:
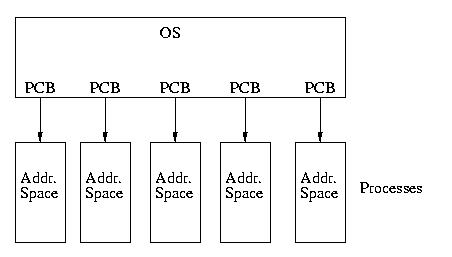
To looking like this:
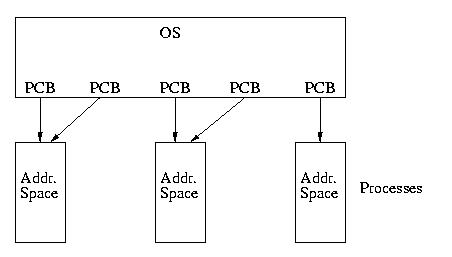
To the user-thread library, the LWP appears to be a virtual processor on which the application can schedule a user thread to run. Each LWP is attached to a kernel thread, and it is kernel threads that the operating system schedules to run on physical processors (Ch 5.).
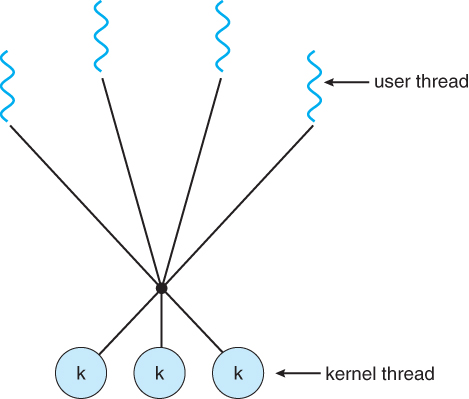
Many-to-Many Model
Based on LWPs, the many-to-many model mutiplexes many user-level threads to a smaller or equal number of kernel threads. Developers can create as many user threads as necessary, and the corresponding kernel threads can run in parallel on a mutiprocessor.
User-level and Kernel-level Multithreading
The key difference between explicitly user-level thread libraries (e.g., pthread or windows.h) and implicitly kernel-level thread abstractions (e.g., thread pools, OpenMP, or GCD) lies in control granularity and abstraction level, which affects how threads are managed and who is responsible for managing them.
1. User-Level Thread Libraries (Explicit Control)
Examples: pthread (POSIX threads), windows.h (Windows threading API)
Characteristics:
- Explicit Thread Management:
The programmer directly creates, manages, and synchronizes threads using APIs likepthread_create,pthread_join, orCreateThread. - Fine-Grained Control:
The library exposes lower-level primitives, allowing the programmer to:- Decide when and how to create threads.
- Explicitly synchronize threads with mutexes, condition variables, etc.
- Handle thread termination and resource cleanup.
- User-Space Scheduling:
If implemented as purely user-level threads (like in the Many-to-One model), the kernel may not even be aware of these threads, and the thread library handles scheduling in user space. This provides lightweight thread management but can suffer from blocking issues.
2. Kernel-Level Thread Libraries (Implicit Abstractions)
Examples: Thread pools, OpenMP (omp.h), Grand Central Dispatch (GCD)
Characteristics:
- Higher-Level Abstractions:
These libraries or frameworks hide most of the low-level thread management details from the programmer. Instead of directly managing threads, you typically submit task or use parallel constructs, and the system determines how threads are allocated. - Kernel-Managed Threads:
These abstractions often rely on kernel threads for execution, meaning the kernel scheduler handles thread creation, termination, and context switching. - Dynamic Resource Management:
They dynamically adjust thread usage to match the available hardware resources (e.g., CPU cores) and workload. For example:- Thread pools reuse threads to minimize thread creation and destruction overhead.
- OpenMP dynamically distributes work across threads with constructs like
#pragma omp parallel for. - GCD (on Apple platforms) uses queues to schedule tasks onto kernel threads efficiently.
Why They “Seem the Same” to Programmers
From a usability perspective, they may feel similar because:
- Both allow concurrent execution.
- The higher-level abstractions are designed to make concurrency easier, hiding the underlying complexity.
However, the level of abstraction and degree of control are vastly different. If you’re using pthread, you’re explicitly in charge of the threads, while with something like OpenMP or GCD, you’re simply defining tasks, and the framework/library manages everything else.
Reference:
- https://stackoverflow.com/questions/5440128/thread-context-switch-vs-process-context-switch
- https://users.cs.duke.edu/~narten/110/nachos/main/node13.html
- Why Are Threads Needed On Single Core Processors - Core Dumped
- https://stackoverflow.com/questions/15983872/difference-between-user-level-and-kernel-supported-threads
- https://cseweb.ucsd.edu/classes/sp16/cse120-a/applications/ln/lecture4.html
- ChatGPT-4o
- Operating System Concepts, 9th edition