Operating System Concepts: Process Concept
Key objectives
- To learn the notion wof a process - a program in execution.
- To describe the various features of processes, including scheduling, creation, and termination.
- To introduce interprocess communication using shared memory and message passing.
Process Concept
1. The process
Informally, a process can be considered as a program in execution. While a program is a passive entity (often called an executable file), a process is an active entity with a PC spcifying the next instruction to execute and a set of associated resources.
So what do we mean by the term “resources”? We know that a process is more than the program code, which is known as the text section, it also includes the current activity and the contents of the processor’s registers. A process also includes the runtime process stack, which contains temporary data, and a data section, which contains global variables, and a heap, which is memory that is dynamically allocated during process run time. Following diagram shows the structure of a process in memory: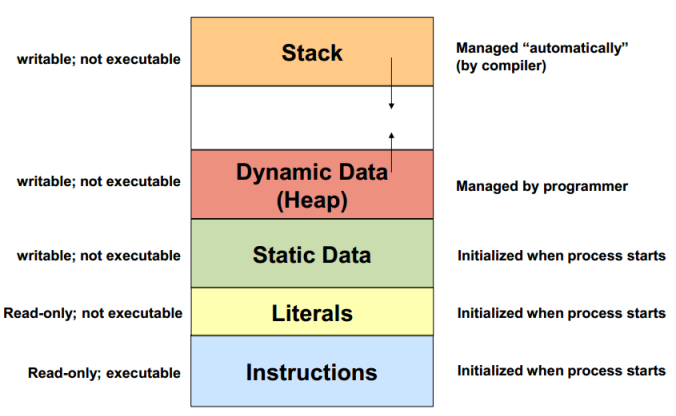
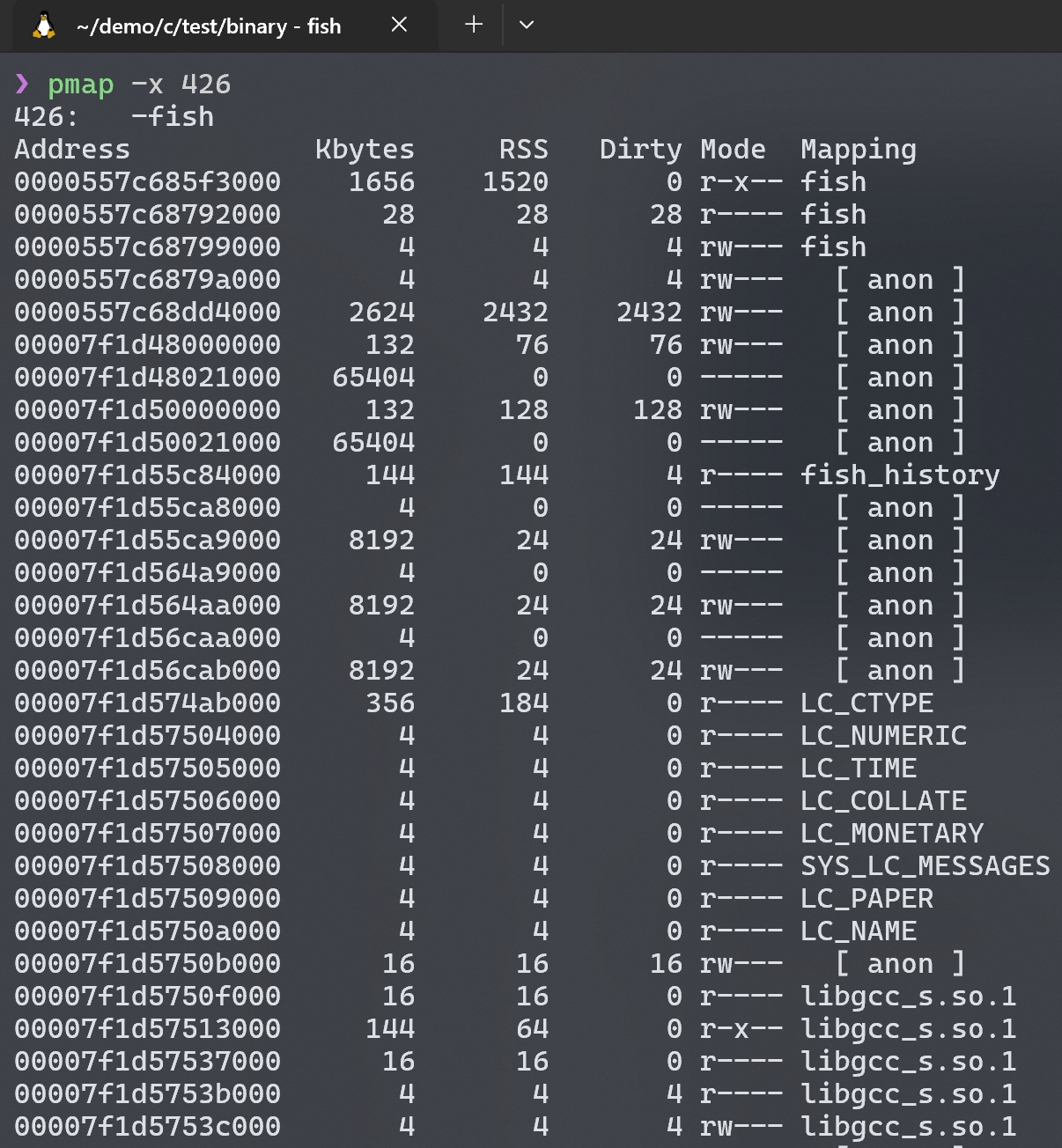
补充:Linux 上查看进程地址空间
- 查看
/proc/<PID>/maps文件
- 直接读取内核提供的虚拟文件,显示进程的完整内存布局(代码段、堆、栈、共享库等)。

- 使用
pmap命令
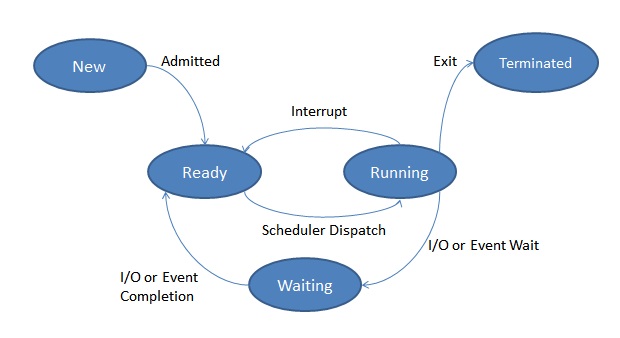
2. Process state
A process may be in one of the states:
- New: The process is being created.
- Running: Instructions are being executed.
- Waiting: The process is waiting for some event to occur (such as an I/O completion).
- Ready: The process is waiting to be assigned to a processor.
- Terminated: The process has finished execution.
3. Process Control Block
In the foregoing text we mentioned the structure of process in memory, which I think is the “memory’s view” of the process. Each process is represented in the operating system by a process conrol block (PCB), which I think is essentially a “scheduler’s view” of the process.
PCB holds the metadata necessary for the OS to manage the process, containing many pieces of information:
- Process state
- Program counter
- CPU registers
- CPU-scheduling information (Ch 5.)
- Memory-management information (Ch 8.)
- Accounting information: including the amount of CPU and real time used, time limits, account number, process numbers, etc
- I/O status information: the list of I/O devices allocated to the process, a list of files, etc
So, while the process structure in memory reflects the actual memory layout and runtime environment of the process, the PCB serves as the abstracted record that the OS scheduler uses to manage and control process execution.
Here is a more detailed introduction of PCB: https://www.geeksforgeeks.org/process-control-block-in-os/
Process Scheduling
The objective of mutiprogramming is to have some process running at all times, to maximize CPU utilization. The objective of time sharing is to switch the CPU among processes to so frequently that users can interact with each program while it is running. To meet this objectives, the process scheduler selects an available process for program execution on the CPU.
1. Scheduling queue
Scheduling queue is the place where a process will be selected for execution. A common representation of process scheduling is a queueing diagram: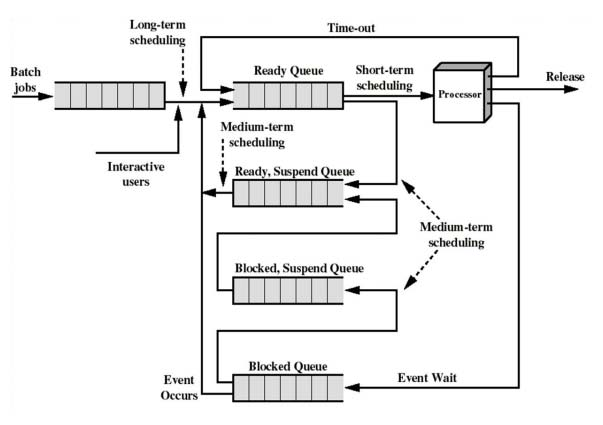
2. Scheduler
The selection process we mentioned is carried out by the appropriate scheduler. Typically, there are two types of schedulers: long-term scheduler and short-term scheduler.
- long-term scheduler (job scheduler): selects processes from the pool and loads them into memory
- short-term scheduler (CPU scheduler): selects from among the processes that are ready to execute and allocates the CPU to one of them
It is important that the long-term scheduler select a god process mix of I/O-bound process and CPU-bound process, to make maximized utilization of CPU and other peripherals.
Operations on Processes
1. Process creation: fork()&exec()
When a process creates a new process, it invokes fork() system call, then two processes will exist: the parent and the child. They each have their own independent memory space, created as a duplicate of the parent process’s memory image at the time of the fork(). So, while they initially share the same memory contents, they don’t share the same memory space—any changes in the memory of one process do not affect the other.
补充:为什么创建进程是设计为
fork()的复制,而非 OS 直接 spawn 或 create ?
1. 历史与设计哲学
Unix 的早期设计(1970 年代)强调 简单性 和 模块化,fork() 的机制完美契合了这一理念:
- 最小化内核功能:
fork()只需复制现有进程的地址空间,而不需要在内核中实现复杂的“启动新程序”逻辑。启动新程序的任务被分离到exec()函数中,两者组合使用(fork()+exec())提供了极大的灵活性。 - 复用现有逻辑:通过
fork()复制父进程,子进程可以直接继承父进程的环境(如文件描述符、信号处理、权限等),无需重新配置,减少了重复代码。
- 性能优化:写时复制(Copy-On-Write, COW)
虽然fork()表面上是“复制整个进程”,但现代操作系统通过 写时复制 技术大幅优化了其性能:
-
延迟物理内存复制:
fork()后,父子进程共享同一物理内存,直到某一方尝试修改内存页时,才会触发实际的复制。这避免了不必要的内存开销。 -
高效且透明:COW 使得
fork()的时间复杂度接近 O(1),即使父进程占用大量内存,fork()仍能快速完成。3. 灵活性与控制
fork()+exec()的组合提供了精细的进程控制能力: -
父子进程共享初始化状态:子进程可以继承父进程的上下文(如打开的文件、信号处理函数、环境变量等),方便父子协作(例如管道通信)。
-
中间步骤的定制:在
fork()之后、exec()之前,子进程可以修改自身环境(如重定向标准输入输出、调整权限、关闭不需要的文件描述符),而无需改动父进程或内核代码。4. 与
spawn或create的对比
直接提供spawn或create的接口(如 Windows 的CreateProcess)看似更简洁,但存在以下权衡: -
灵活性受限:一步到位的
spawn需要在接口中预设所有可能的参数(如环境变量、文件描述符继承规则等),导致接口复杂化。 -
性能开销:每次创建进程都需重新初始化所有资源(如内存空间、文件描述符),而
fork()通过 COW 和继承机制避免了重复初始化。 -
与 Unix 工具链的兼容性:
fork()的设计与 Unix 的管道(pipe)、信号(signal)等机制深度集成,直接spawn可能破坏这种生态。
The exec() system call replaces the current process’s memory with a new program. When a process (either the parent or the child) calls exec(), it loads the specified binary executable into its own memory space, overwriting the existing program code, stack, heap, and data segments. This effectively “destroys” the memory image of the process that existed before the exec() call and replaces it with a new one.
This replacement doesn’t affect the other process, though:
- Independent Memory Spaces: After
fork(), the parent and child processes have separate memory spaces. So when the child (or the parent) callsexec(), it only affects that process’s memory, not the other’s. - Process Continuation After
exec(): After callingexec(), the process (now with a new memory image) continues execution at the entry point of the new program, rather than the program that was previously running. It can still execute because theexec()call replaces the memory but not the process ID (PID). The process itself persists, but its memory contents are now those of the new program.
2. Process termiation: wait()&exit()
A process terminates when it finishes executing its final statement and asks the operating system to delete it by using the exit() system call. At hat point, the process may return a status value to its parent proess (via the wait() system call).
After the exit() sys call, all the resources of the process—including physical and virtual memory, open files, and I/O buffers—are deallocated by the operating system. However, it entry in the process table must remain there until the parent calls wait(), because the process table contains the process’s exit status.
Interprocess Communication
Cooperating processes require an interprocess communicaton (IPC) mechanism that will allow them to exchange data and information with each other. There are two fundamental models of IPC: shared-memory and message-passing.
1. Shared-memory model
In this IPC Model, a shared memory region is established which is used by the processes for data communication. This memory region is present in the address space of the process which creates the shared memory segment. The processes that want to communicate with this process should attach this memory segment to their address space.
Here’s a basic outline of how shared memory IPC operates:
- Creation of Shared Memory Segment: A process usually the parent, creates a shared memory segment using the system calls like
shmget()in Unix-like systems. This segment is assigned the unique identifier (shmid). - Attaching to the Shared Memory Segment: The Processes that need to access the shared memory attach themselves to this segment using
shmat()system call. Once attached the processes can directly read from and write to the shared memory. - Synchronization: Since multiple processes can access the shared memory simultaneously synchronization mechanisms like semaphores are often used to the prevent race conditions and ensure data consistency.
- Detaching and Deleting the Segment: When a process no longer needs access to the shared memory it can detach from the segment using
shmdt()system call. The shared memory segment can be removed entirely from system usingshmctl()once all processes have the detached.
2. Message-passing model
Message passing provides a mechanism to allow processes to communicate and to synchronize their actions without sharing the same address space. A message-passing facility provides at least two operations: send(message)andreceive(message). To satisfy these purposes, a logical communication link is needed.
Although the message queue is not maintained by the processes but the kernel, synchronization problem still exists. There are two types of implements: sychronous message passing (blocking) and asynchronous message passing (non-blocking).
| Shared Memory Model | Message Passing Model |
|---|---|
| The shared memory region is used for communication. | A message-passing facility is used for communication. |
| It is used for communication between processes on a single processor or multiprocessor system where the communicating processes reside on the same machine as the communicating processes share a common address space. | It is typically used in a distributed environment where communicating processes reside on remote machines connected through a network. |
| The code for reading and writing the data from the shared memory should be written explicitly by the Application programmer. | No such code is required here as the message-passing facility provides a mechanism for communication and synchronization of actions performed by the communicating processes. |
| It provides a maximum speed of computation as communication is done through shared memory so system calls are made only to establish the shared memory. | It is time-consuming as message passing is implemented through kernel intervention (system calls). |
| Here the processes need to ensure that they are not writing to the same location simultaneously. | It is useful for sharing small amounts of data as conflicts need not be resolved. |
| Faster communication strategy. | Relatively slower communication strategy. |
| No kernel intervention. | It involves kernel intervention. |
| It can be used in exchanging larger amounts of data. | It can be used in exchanging small amounts of data. |
| Example- - Data from a client process may need to be transferred to a server process for modification before being returned to the client. |
Example- - Web browsers - Web Servers - Chat program on WWW (World Wide Web) |
Communication in Client-Server system
1. Sockets
Sockets are designed to provide low-level communication mechanisms. They are (1) Closer to the network layer and (2) more flexible but require more work from the developer to interpret the data.
What’s the format of data in connection between sockets
We define sockets with the term "low-level " because sockets provide a way to send and receive raw data (byte streams). It is up to the developer to define the meaning, structure, and interpretation of these bytes. Sockets do not impose any structure on the data; they only transport it as an unstructed stream of bytes. In this way, the application must define a protocol to add structure, such as delimiters, headers, or serialization formats.
Designing purpose
The purposes of socket are to provide a general-purpose communication mechanism and to focus on how to transmit data rather than its meaning.
Here’s an example. When transmitting a message like "Hello, World!" over a socket, it’s sent as a sequence of bytes:
1 | 72 101 108 108 111 44 32 87 111 114 108 100 33 |
The receiver must have prior knowledge of how to interpret these bytes:
- Are they plain text? Binary data? A serialized object?
- Is there a delimiter to separate multiple messages?
2. Remote Procedure Calls
Procedure calls
A procedure call is a mechanism in programming where one piece of code (the caller) invokes a procedure or function defined elsewhere. During a procedure call:
- The caller temporarily suspends its execution.
- Control transfers to the invoked procedure.
- After the procedure finishes execution, control returns to the caller, optionally with a return value.
That seems like a simple function call, which definitely satisfies synchronization and occurs in the same address space.
RPC
RPC (Remote Procedure Call) systems are designed to make remote communication look and feel like a local function (procedure) call. To achieve this, they operate at a higher level of abstraction and handle the complexity of encoding/decoding data automatically.
Instead of directly send the raw data, the RPC framework serializes these parameters into a structured message format for transmission, and then convey them to sockets, that’s why we called them “higher level”.
Message Structure:
- Messages are structured and follow a well-defined format (e.g., Protocol Buffers in gRPC, XML in XML-RPC, or JSON in JSON-RPC).
- Each message includes metadata, method names, arguments, and return values.
- This structure ensures that the receiver (server or client) knows how to decode and interpret the data.
Designing purpose
RPC not only simplifies distributed computing but also focus on what to transmit (parameters and return values), not how to transmit it.
Difference and relation with sockets:
In essence, RPC builds on sockets to abstract away low-level details and provide a structured, user-friendly interface for developers.
- Sockets provide a flexible, low-level mechanism for transmitting unstructured byte streams, leaving structure and interpretation to the application developer.
- RPC adds an abstraction layer, automatically structuring messages (parameters, metadata, etc.) to simplify distributed computing and make remote calls feel like local ones.
In an RPC call, a function like getUserData(123) could be serialized into a message:
1 | { |
The server processes this structured message and sends back a structured response:
1 | { |
3. Pipes
A pipe acts as a conduit allowing two processes to communicate. In completing a pipe, four issues must be considered:
- Does the pope alow bidirectional communication or unidirectional?
- If two-way communication is allowed, is it half duplex or full duplex?
- Must a relationship (such as parent-child) exist between the communicating processes?
- Can the pipes communicate over a network, or must the processes reside on the same machine?