Standford CS144 Lab 1
Lab 1 项目构建

由于我对git不是很熟练,所以拉取和合并的操作有点麻烦。首先git clone -b lab1-startercode <url>拉取的是别人仓库 lab1 的 start code 到本地,然后git remote rm origin删除与远端仓库的联系,git remote add origin <[email protected]:usrname/reposname.git>和自己的远端仓库联系(<url>的话GitHub已经不支持用户密码登录了,最好是用SSH),再push到远端的一个新的分支上(我的分支名称叫lab1,用来保存starter code)。接着就和文档给出的步骤一样,git fetch同步一下,然后git merge origin/lab1,不出所料会发生merge conflict。
不用慌,进到文件夹里一点点 merge 就好。冲突解决完后git add ->git commit->git push行云流水推到 lab0 的分支上,最后make编译完成了项目初始化。
实验要求
总览 Lab 0/1/2/3/4 框架
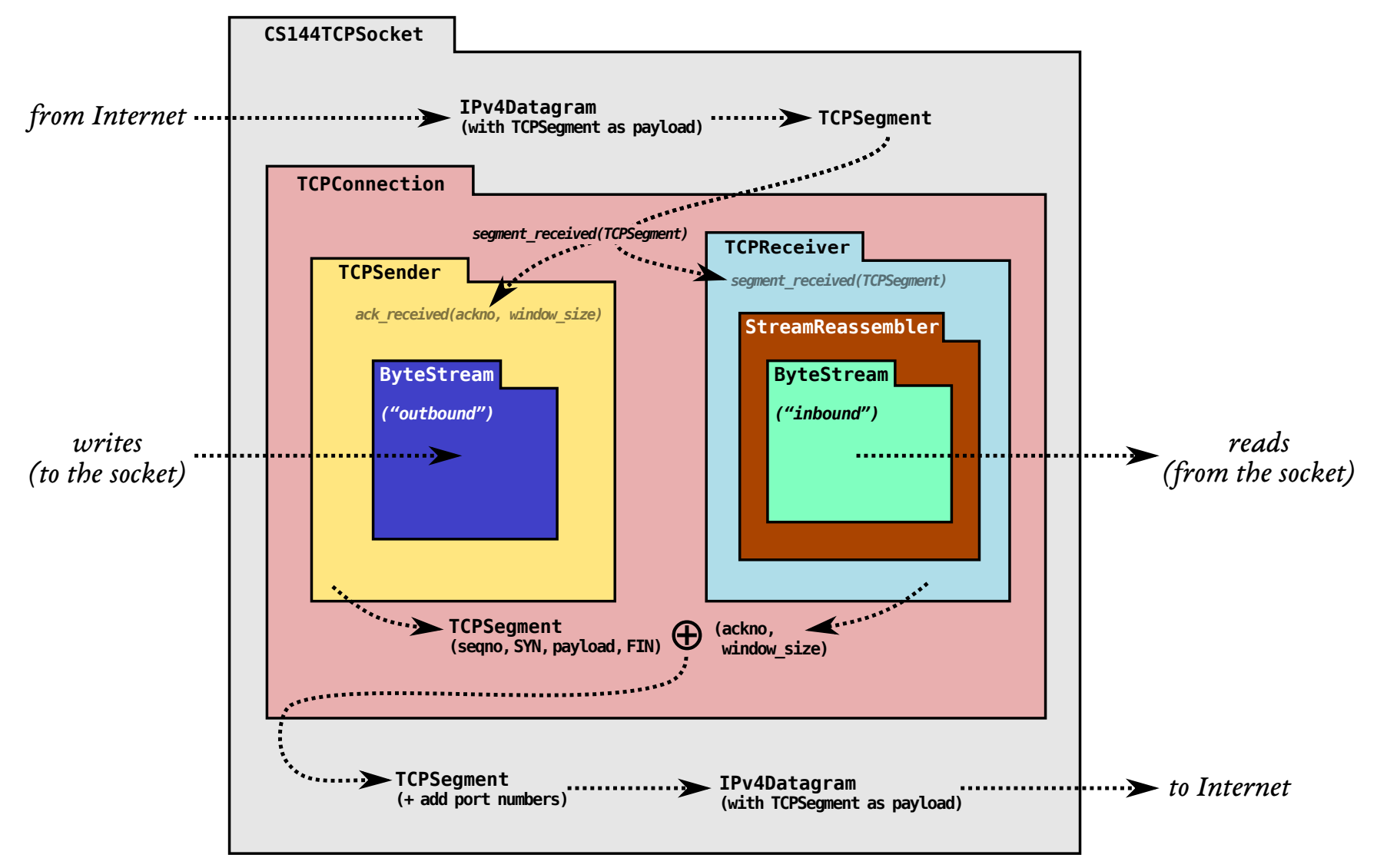
Figure: The arrangement of modules and dataflow in your TCP implementation. The ByteStream was Lab 0. The job of TCP is to convey two ByteStreams (one in each direction) over an unreliable datagram network, so that bytes written to the socket on one side of the connection emerge as bytes that can be read at the peer, and vice versa. Lab 1 is the StreamReassembler, and in Labs 2, 3, and 4 you’ll implement the TCPReceiver, TCPSender, and then the TCPConnection to tie it all together.
整个实验将 TCP 模块化分开来完成,最后把几个组件合在一起实现 TCP。在Lab 0的webget函数中,我们直接使用了系统提供的 TCP("using Linux’s built-in implementation of the Transmission Control Protocol (TCP)"),在此之上我们使用 TCP 提供的服务实现了客户端socket。而接下来我们把视角移动到 socket 面向运输层的一端,将实现自己的 TCP,也就是说我们要在一个不可靠的网络(网络层)上实现对上层(应用层)提供的服务。
Over the next four weeks, you’ll implement TCP, to provide the byte-stream abstraction between a pair of computers separated by an unreliable datagram network.
Lab 1 要求
In Lab 1, you’ll implement a stream reassembler—a module that stitches small pieces of the byte stream (known as substrings, or segments) back into a contiguous stream of bytes in the correct sequence.
在Lab 1中,我们将要完成一个流重组器(stream reassembler),在上面的框架中可以看到它是我们实现TCPReceiver组件的一个子组件,其功能也很清晰:由于网络不可靠,所以数据报可能丢失、失序或者重复(没有考虑出错),流重组器读取这些数据报并将它们转换为可靠的字节流,写入BytesSream中。
编写代码和调试
关于实现的思考
我们要实现的,其实就是在capacity大小的内存限制下,完成子字符串的合并!说起合并,我记起之前在 Leetcode 上做过一道数组合并的问题,还想到了 B 树的合并。
对于容器的选择(我的 C++不熟练,很多容器都不了解),我看网上有些朋友使用std::vertor,也有选std::set模拟缓冲区的,还有选std::map的。我选择的是std::map,key是size_t类型而value是string类对象,好像运用不到前面无端联想的东西。不得不说map进行合并实在是太繁琐了,要考虑到很多种情况(重复代码也很多),暴力模拟了 200 多行 😭,包含了整整 5 层条件判断 😭。由于太多种情况需要分析了,难免会有疏漏,最后我实在不想修补了,于是便放弃了map。后面我一想,直接每一个序号对应一个字节不久简单很多了吗!!
看到其他人三四十行就解决了,而我两百行写了一整天,感觉自己真的很菜。当然优化是后话了,至少先把实验完成了,再去考虑减少重复代码(函数封装),提高性能(选择其他数数据结构)等问题。
流程模拟
- 输入的子字符串可以由三个量唯一描述:字符串值、长度、第一个字节的序号。我们在
push_substring中可以看到输入中还有一个量eof,这代表的是substring流是否到达末尾,所以我并没有把它算作子字符串的属性之一。 - 我们被限制使用
capacity大小的内存,这个内存是由ByteStream中的缓冲区(下图绿色部分)和SreamReassembler自身的缓冲区(下图红色部分)所共有的。前者用于缓冲已经重组好但并未被应用程序读取的有序可靠字符串,后者用于缓存接收到的乱序子字符串。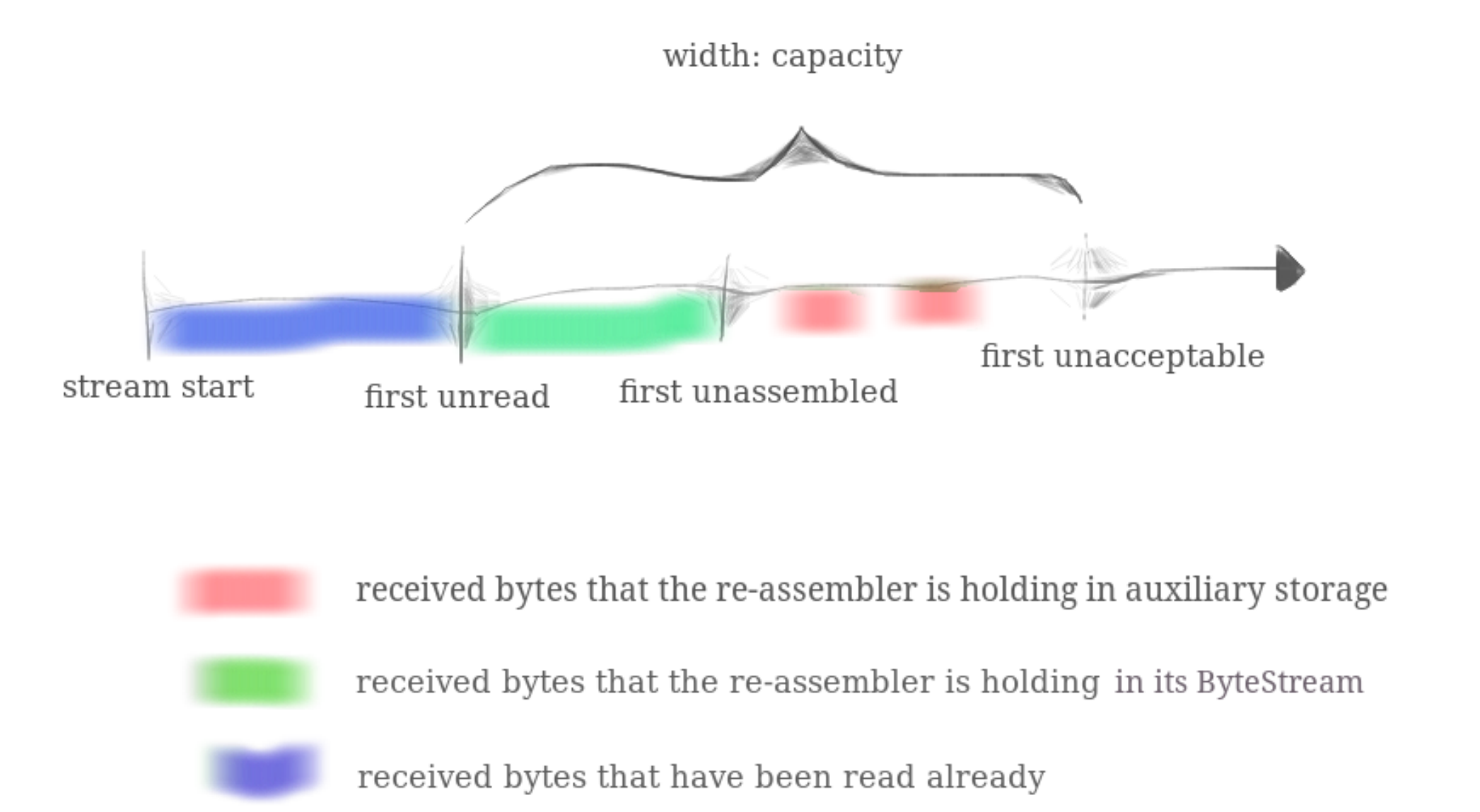
- 注意: 接受到的子字符串可能是乱序、重复的,就如同实际网络中一样。这里的有一些注意点是实验文档里没说清楚的(不足之处),我通过调试测试用例才发现的(面向测试用例编程 😵)。
- 子字符串可能完全位于蓝色/绿色(已读出/已写入
ByteStream)部分,需要直接丢掉 - 子字符串可能有一部分是已经写入
ByteStream(绿色),而有一部分是未写入的(红色),需要进行裁剪 - 子字符串可能全是红色部分,实验要求我们在红色部分不能有重叠的字符串,也就是说读入的时候我们要对它进行合并才能缓存到
Reassembler中 - 字符串可能是包含
EOF信息的空字符串,关键在EOF的处理
- 子字符串可能完全位于蓝色/绿色(已读出/已写入
调试
std: :map<size_t, std: :string>版
根据以上的思路,我尝试用一个测试用例看看具体的过程,下面是fsm_stream_reassembler_single.cc中的一个例子。
初始化
capacity大小为 8,然后输入序号为 0 的"abc"子字符串,直接缓存到ByteStream中,下一个期待接受到的序号应该是 3。之后再输入序号为 6 的"ghX"字符串,且最后一个字节是字符串流的末尾,由于前面还有字节未接收到,因此先缓存到Reassembler的缓冲区中。之后又输入了序号为 2 的字符串"cdefg",由于序号 2 的字节已经写入ByteSream了,所以我们会对字符串进行裁剪,相当于输入的是序号为 3 的字符串"defg"。注意到此时缓冲区中有已重组的字符串"abc"+未重组的字符串"ghX",剩余内存大小为 2,也就是说我们只能缓存序号为 3 的"de"字符串,恰好是期望的下一个字节序号,立即写入到ByteStream中。此时ByteStream缓冲区应该有字符串"abcde",而Reassembler缓存区中应该有序号为 6 的子字符"ghX",结果与测试用例不符合!
1 | { |
从测试用例来看,是先合并了"defg"和"ghX",此时缓存区有序号为 3 的字符串"defghX",而在写入ByteStream时由于内存限制丢弃了最后一个字节!文档中写道 "Receive a substring and write any newly contiguous bytes into the stream. The StreamReassembler will stay within the memory limits of the capacity. Bytes that would exceed the capacity are silently discarded."是说超过 capacity 大小的字节会丢弃,所以我认为应该是在输入字符串时就把它丢弃的(错误)。
其实这种想法和具体实践中的网络包收发是相违背的。在处理网络包失序时,如果缓冲区空间有限并且必须丢弃某些数据包,需要考虑的主要原则是尽量保持数据的有序性并减少重复的传输请求,所以会优先丢弃序号较大的已缓存的数据,这种策略的主要思想是保持数据流的连续性,优先确保期望的下一个序号的数据包能够尽快被接收到。
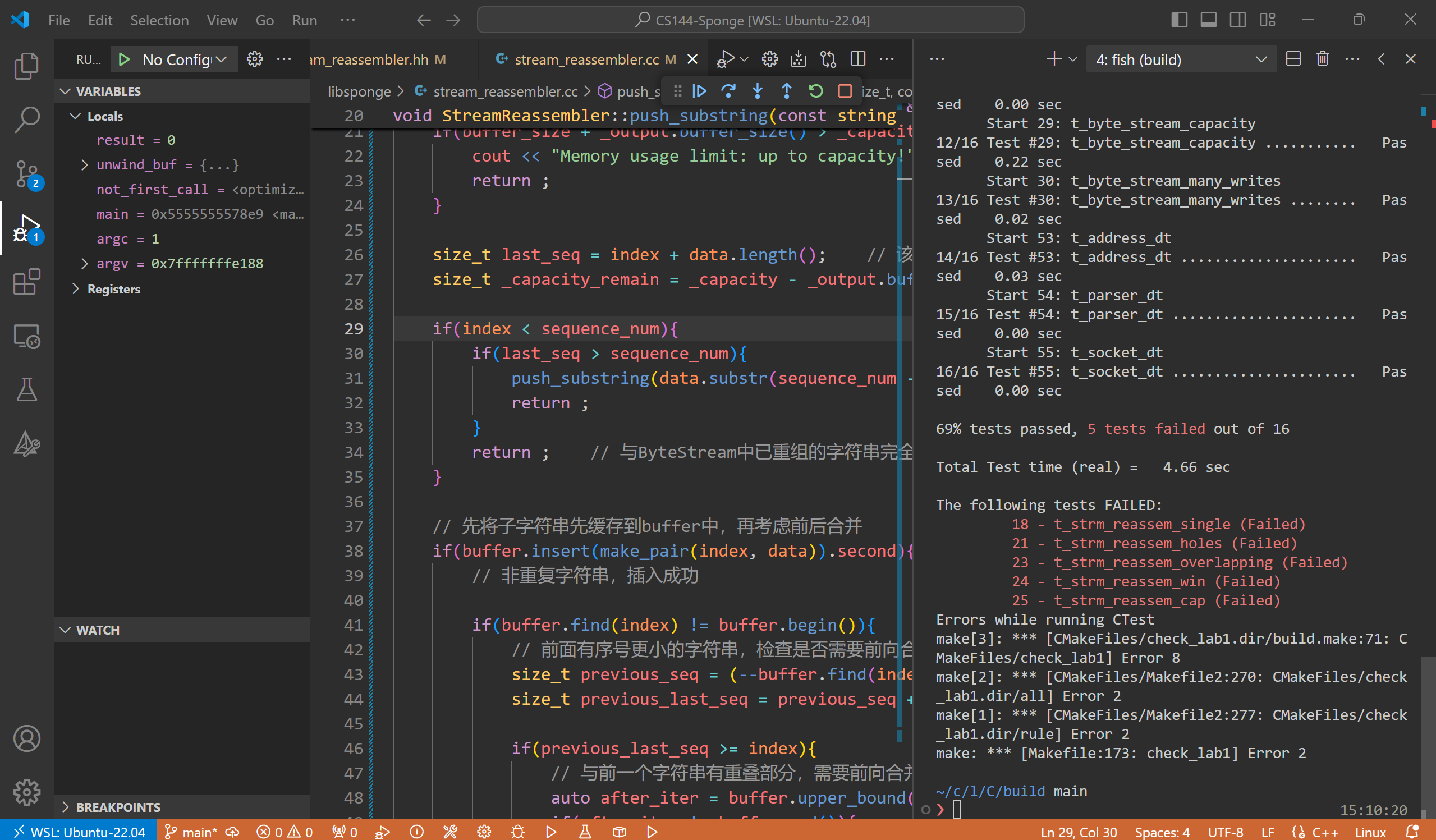
在后续调试过程我发现我还有一些情况没有考虑到,而这种映射关系模拟起来过于繁琐,因此放弃了映射到std::string,尝试映射到std::char重新写一遍。
std: :map<size_t, char>版
实现过程
- 先对接收的子字符串进行裁剪,然后缓存到
StreamReassembler中 - 在
capaity缓冲区大小的限制下,采取优先丢弃序号较大的已缓存字符串的策略,对StreamReassembler缓冲区进行限制 - 判断是否将
StreamReassembler中的重组字符串写入ByteSream中
测试结果
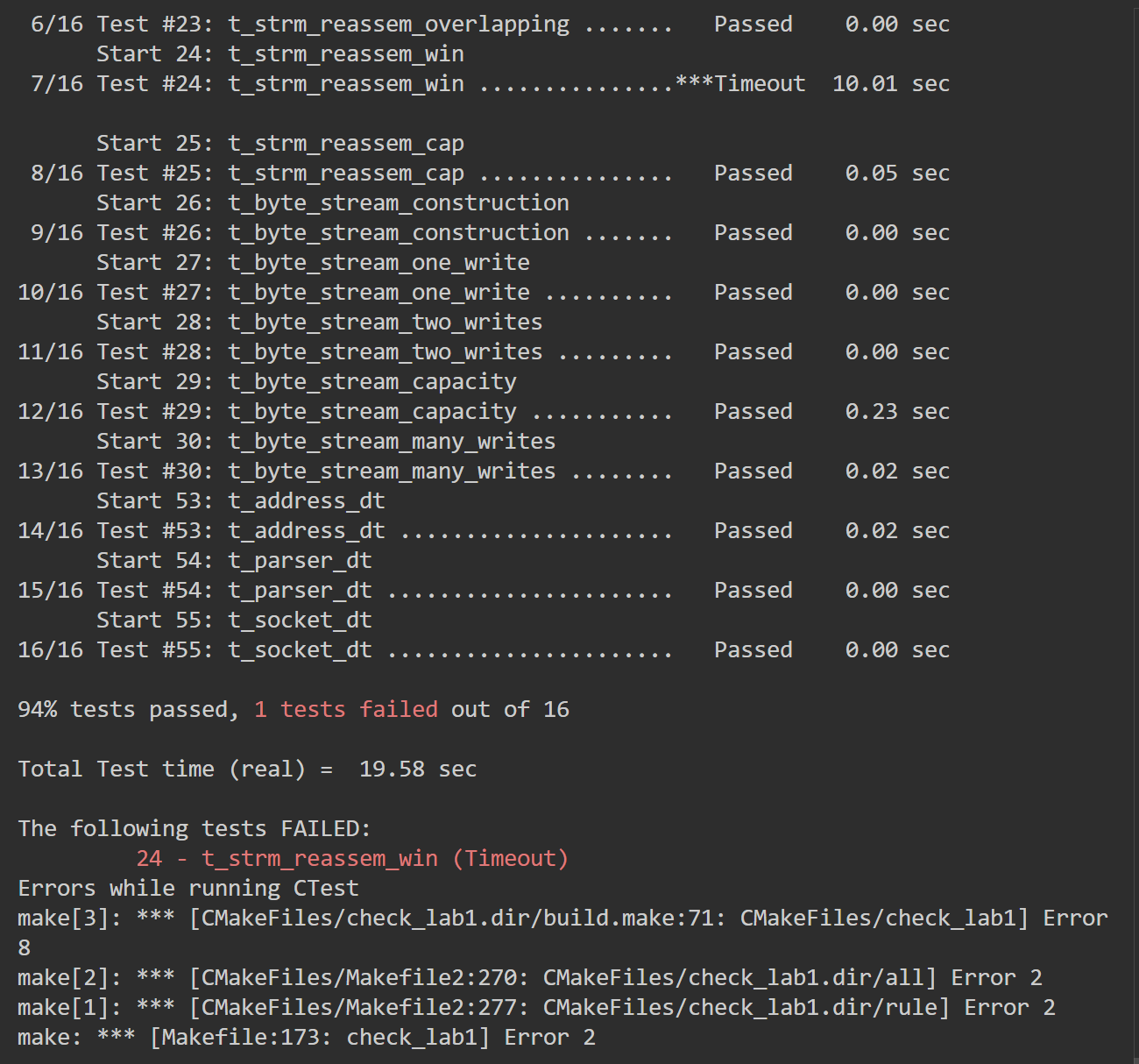
测试用例t_strm_reassem_many和t_strm_reassem_win用时过长
实现代码
1 | /* stream_reassembler.hh */ |
1 | /*stream_reassembler.cc*/ |
总结反思
- 对 C++的 STL 不熟悉,因此在缓冲区的模拟中走了弯路
- 对于基本算法不熟练,需要多刷题提升思维
- 保持初心,但不要钻牛角尖,学会知难而退,学习他人的代码是如何设计构建的,也是学习的一个方法